... many proto-European languages have grammar cases which are absent from the English language. The number of cases that exist in the lexicon depend on the language. For example, in German the ending of a word changes based on how it's used in a sentence. These language nuances are captured by word-counting algorithms as long as the input text is of good quality (grammatically correct). A word-counting reading algorithm associates the low-frequency words in each .-ended sentence.
association dictionary
An association dictionary is a collection of single sentence term associations without the interstitial grammar.
ASSOC1|ASSOC2|ASSOC3
It may be useful to publish a collection of associations for language learners so that they may know what terms are associated in the destination lexicon.
text processing
http://de639-1.blogspot.com/2016/09/nl-wikipedia-text-tweedehands-2nd-hand.html
... an example of text processing using STRINGSRESEARCH software at above url. IQ processing indicates the number of times each word appears in a text of any language. For words that appear uniquely or only once in the text the numberal 1 is omitted and these words are not tagged. All other words are tagged by their frequency in the text.
... words which appear only once in the text are important because they form associations that a native speaker would make when reading the text. The associations can be shown by silhouetting the other higher-frequency words of the text.
numbers
... in a text are replaced by number sign (#) for text processing. This is so that numbers can be converted to word form. The placement of a single number (#), double number (##) and triple number (###) etc. can be analysed within a text of any language provided the numbers are in arabic form (123456...).
intellectual quotient
… is defined in terms of the low-frequency intra-text words. A text can be divided into low-frequency and high-frequency intra-text words. Low-frequency words form terms and associations. High-frequency words are the interstitial context (ie prepositions, conjunctions). The terms and associations can be popped out of the text by eliminating the lower order words.
lexical fluicization
... the process of acquiring the lexical contents of a foreign lexicon or becoming fluent in that language. It is important to acquire the least repeated words first and then grammatically attach them using the more frequently repeated words in the destination lexicon. Often, it is difficult for the language learner to attach the destination lexicon terms without error. The interstitial grammar should be learned after associations have been taught in the corresponding destination lexicon.

.turned.htm file opened in firefox

once saved in the software, the turned file can be opened in any web-browser; in this case firefox which is preferred by STRINGSRESEARCH; the htm tab in the software is a MSFT internet explorer web-browser
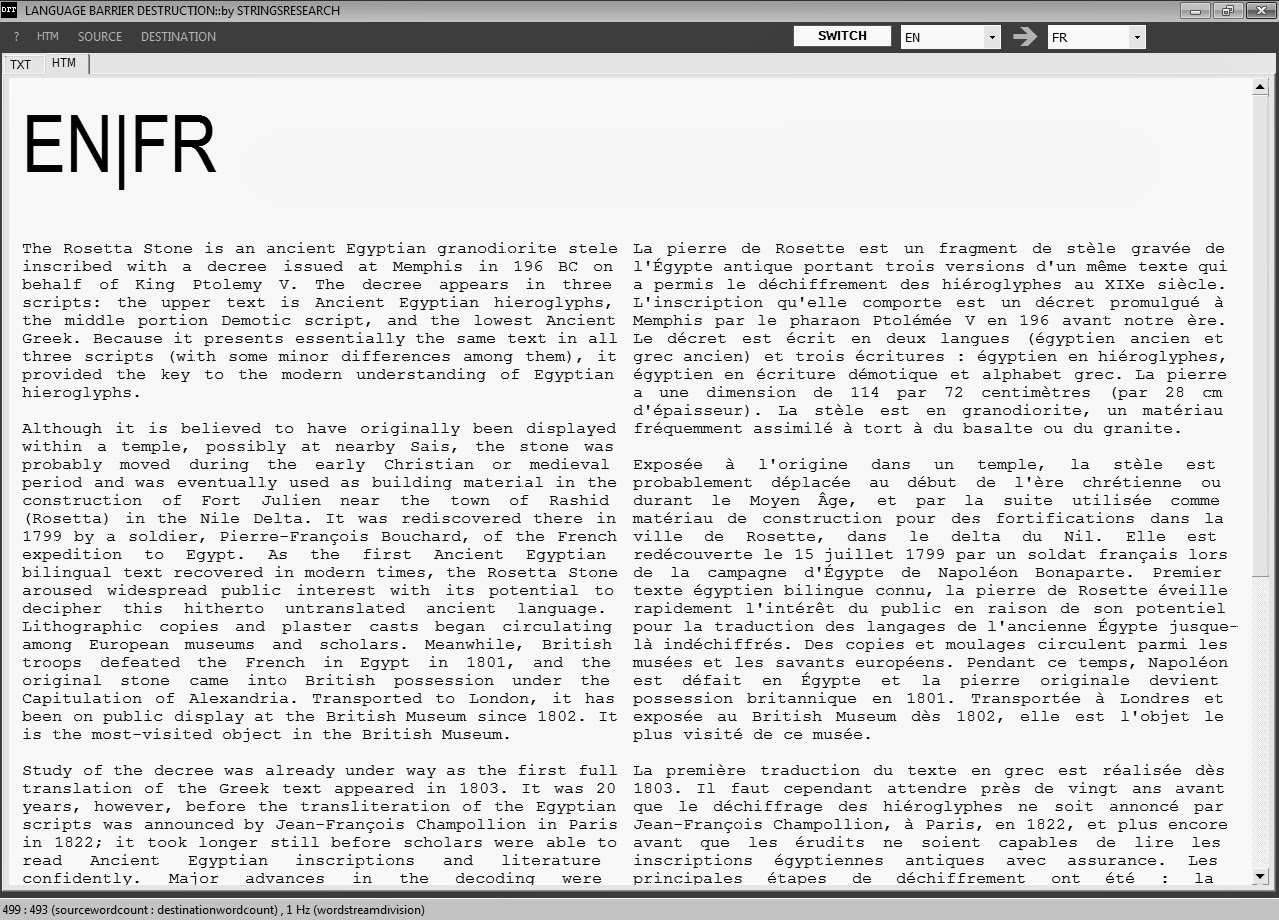
PDFed file created using software
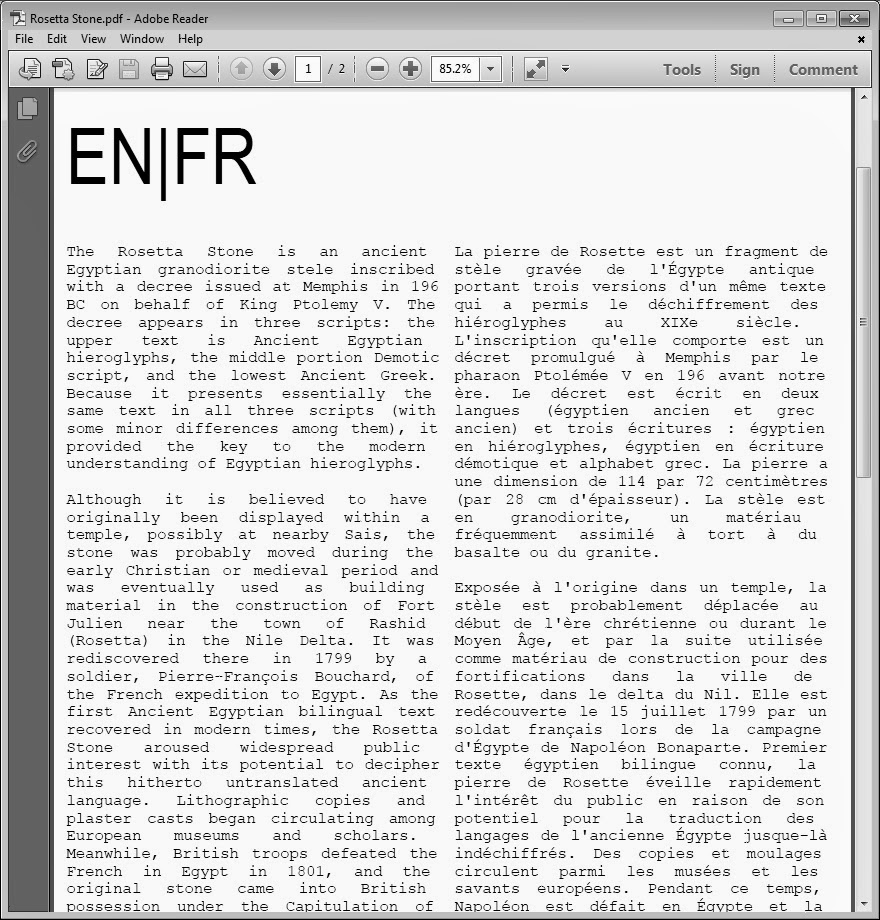
margins set at zero to make full use of e-space; for physical printing suggested that margins be non-zero; e-documents not meant to be printed don't require non-zero margins

order quotient
… is where words are tagged sequentially starting at 1 (one). Used to analyze texts of any language. Every single word can be referred to / annotated by using the number tag that appears in front of it. Lawyers may find this useful. As well poor-quality strings — iow strings that are tainted through the linguistic lense by a foreign lexicon — may be deconstructed by referring to the number-identifiers of the string words.
… not to be confused with word-stream tagging which is used for turning a language from source to destination.
…interesting concept: tagging all a person's electronic words from the time they are born. Each written word can then be referenced by number. How many words has a person written by the end of their life-time ? In what language is each word ?
… not to be confused with word-stream tagging which is used for turning a language from source to destination.
…interesting concept: tagging all a person's electronic words from the time they are born. Each written word can then be referenced by number. How many words has a person written by the end of their life-time ? In what language is each word ?
show log file on exit
… generates and opens txt log file which includes all actions taken during the session and a summary of those actions.
parallel- / bi-text
… a dual language document. Two texts can be compared side-by-side or a single text can be annotated.
destination
… is the language you are translating or turning to. Right-hand text-box in the software. A language is turned over the low-frequency intra-text word points.
.htm
… the extension on internet-documents; which can be viewed in web-browsers, poorly in word-processors and in visual basic. Infrequently occurs as .html.
.turned.htm
… is the extension given to files saved in LITHIUMSTRINGS software. It is an htm web-document file but the preceding turned extension indicates it was created by LITHIUMSTRINGS software. The turned extension is used because, effectively, the file has been “turned” using HERTZIAN LINGUISTICS.
export to clipboard
… once a turn-function has been chosen, export to clipboard may be used to get the htm code on the clipboard for use in a blog post such as at FOREIGNTEXTS.
intellectual quotient with words
… the number of occurrences of a word within a text is given as a hyphenated-number in front of the word. Stream1 has no number in front of it as this is the base association stream.
intellectual quotient with word-silhouette
… actual words are hidden; only information given is intra-text word-frequency and the number of chars (characters) in the word. The number of chars include the Hz-number and •-string. Demonstrates that strings of every language are musical and can be reduced to simple Hz (word-frequency).
show context
… whereas context is hidden with hide context, non-context is hidden with show context.
Subscribe to:
Posts (Atom)
